Intelligible Lip-to-Speech Synthesis with Speech Units
Jeongsoo Choi, Minsu Kim, Yong Man Ro
[Paper] [Code]
Abstract
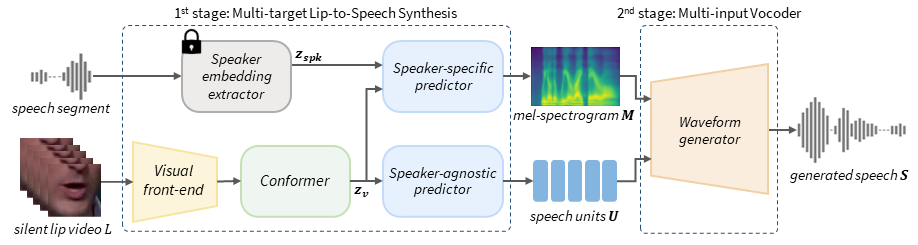
In this paper, we propose a novel Lip-to-Speech synthesis (L2S) framework, for synthesizing intelligible speech from a silent lip movement video. Specifically, to complement the insufficient supervisory signal of the previous L2S model, we propose to use quantized self-supervised speech representations, named speech units, as an additional prediction target for the L2S model. Therefore, the proposed L2S model is trained to generate multiple targets, mel-spectrogram and speech units. As the speech units are discrete while mel-spectrogram is continuous, the proposed multi-target L2S model can be trained with strong content supervision, without using text-labeled data. Moreover, to accurately convert the synthesized mel-spectrogram into a waveform, we introduce a multi-input vocoder that can generate a clear waveform even from blurry and noisy mel-spectrogram by referring to the speech units. Extensive experimental results confirm the effectiveness of the proposed method in L2S.
Random samples from LRS3 Dataset
| Silent video | Ground Truth | Ours (Proposed + AV-HuBERT) |
Ours (Proposed) |
Ours (Proposed w/o aug) |
Multi-Task | SVTS | VCA-GAN | Text |
|---|---|---|---|---|---|---|---|---|
| they are the basis of every action that you take | ||||||||
we don't trust the man |
||||||||
| otherwise millions more will die | ||||||||
| and then something falls off the wall | ||||||||
| and that's powerful | ||||||||
| so the answer to the second question can we change | ||||||||
| they want to be part of it | ||||||||
| we paid two to three times more than anybody else | ||||||||
| and that's why it's been a pleasure speaking to you | ||||||||
| government officials are extremely mad | ||||||||
| but you know what | ||||||||
| thank you very much | ||||||||
| beth israel's in boston | ||||||||
| but we're not there yet | ||||||||
| and they don't need to ask for permission | ||||||||
| how much they do | ||||||||
| so what can we do | ||||||||
| they were wonderful people | ||||||||
| how do you change your behavior | ||||||||
| he could come over and help me |